MPI学习--阻塞通信之缓冲通信模式
通过一个缓冲通信的例子来简单总结下缓冲通信模式。
缓冲通信模式主要用于解开阻塞通信的发送和接受之间的耦合。有了缓冲机制,即使在接收端没有启动相应的接收情况下,在完成消息数据到缓冲区的转移后发送端的阻塞发送函数也可以返回。
但缓冲方式带来了额外的内存到内存的复制开销,会导致一定的性能损失和资源占用。的确,每个进程都要在堆里分配内存然后注册成为缓冲区。
缓冲区的使用并不能改变发送和接受之间的语义关系,及不能改变程序的正确性。
与标准模式由于以来MPI环境提供的缓冲机制而受到远端进程状态左右不同,缓冲发送完成与否不会受远端匹配进程状态的影响。但当消息大小超过缓冲区容量时,会报错。
缓冲通信模式如下图所示,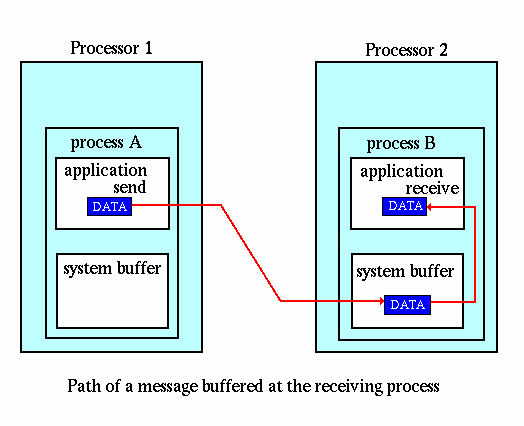
然后就写了个缓冲通信的例子来实际操作下:
1 |
|
上面的代码有一些针对缓冲通信模式的新内容:
获取每个消息所需缓冲区大小
1
2
3
4int MPI_Pack_size(int incount,
MPI_Datatype datatype,
MPI_Comm comm,
int *size)使用
PACK_SIZE来为每个消息计算其使用buffer的大小。此函数用来返回打包一个消息所需要的最大上限,以字节为单位。定义缓冲方式需要的总的内存开销上界
1
bufsize = 3*MPI_BSEND_OVERHEAD + s1 + s2 + s3;
The MPI_BSEND_OVERHEAD gives the maximum amount of space that may be used in the buffer for use by the BSEND routines in using the buffer. This value is in mpi.h (for C) and mpif.h (for Fortran).
这样用户就可以自定义用于缓冲通信的缓冲区的大小。装配用于通信的缓冲区
1
int MPI_Buffer_attach(void *buffer, int size)
此函数就将用户自己开辟的内存空间注册为一个用于缓冲通信的缓冲区。
移除一个当前存在的用于缓冲通信的缓冲区
1
int MPI_Buffer_detach(void *buffer_addr, int *size)
这里需要注意的是第一个参数
void *buffer_addr是个指针的指针,这与MPI_Buffer_attach中的参数并不相同
但是这里的移除并不是释放该进程申请的内存,因此在最后还要将内存释放掉。
将这个例子进行编译执行的结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14[zjshao@master ch02]$ mpiexec -host node01 -n 2 bsendrecv.x
Before receiving msg1 on proc 1, t = 1467968222.659515
Before sending msg1 from proc 0, t = 1467968222.659531
After sending msg1 from proc 0, t = 1467968222.659563
After receiving msg1 on proc 1, t = 1467968222.659565
Before receiving msg2 on proc 1, t = 1467968222.659572
Before sending msg2 from proc 0, t = 1467968222.659571
After sending msg2 from proc 0, t = 1467968222.659592
Before sending msg3 from proc 0, t = 1467968222.659599
After receiving msg2 on proc 1, t = 1467968222.659595
Before receiving msg3 on proc 1, t = 1467968222.659600
After sending msg3 from proc 0, t = 1467968222.659616
After receiving msg3 on proc 1, t = 1467968222.659619
[zjshao@master ch02]$
为了能体现缓冲通信模式的特点,加几个阻塞函数在两个进程中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24if (rank == src)
{
fprintf(stderr, "Before sending msg1 from proc %d, t = %f\n", rank, MPI_Wtime());
MPI_Bsend(msg1, MSG1LEN, MPI_CHAR, dest, 1, comm);
fprintf(stderr, "After sending msg1 from proc %d, t = %f\n", rank, MPI_Wtime());
...
MPI_Barrier(comm);
MPI_Buffer_detach(&buf, &bufsize);
}
else if (rank == dest)
{
MPI_Barrier(comm);
fprintf(stderr, "Before receiving msg1 on proc %d, t = %f\n", rank, MPI_Wtime());
MPI_Recv(rmsg1, MSG1LEN, MPI_CHAR, src, 1, comm, MPI_STATUS_IGNORE);
fprintf(stderr, "After receiving msg1 on proc %d, t = %f\n", rank, MPI_Wtime());
...
MPI_Buffer_detach(&buf, &bufsize);
}
重新编译执行:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15[zjshao@master ch02]$ mpicc bsendrecv.c -o bsendrecv.x
[zjshao@master ch02]$ mpiexec -host node01 -n 2 bsendrecv.x
Before sending msg1 from proc 0, t = 1467968941.629696
After sending msg1 from proc 0, t = 1467968941.629726
Before sending msg2 from proc 0, t = 1467968941.629733
After sending msg2 from proc 0, t = 1467968941.629745
Before sending msg3 from proc 0, t = 1467968941.629750
After sending msg3 from proc 0, t = 1467968941.629769
Before receiving msg1 on proc 1, t = 1467968941.629784
After receiving msg1 on proc 1, t = 1467968941.629812
Before receiving msg2 on proc 1, t = 1467968941.629818
After receiving msg2 on proc 1, t = 1467968941.629823
Before receiving msg3 on proc 1, t = 1467968941.629827
After receiving msg3 on proc 1, t = 1467968941.629830
[zjshao@master ch02]$
可见,发送动作可以在执行后立即返回,MPI环境在底层完成了消息的传递,也就是发送动作将数据送达到接收端,进入接受缓冲区,然后返回就好了,接收端会在接受缓冲区中将数据解析完成接受操作。
现在我们把阻塞函数放到发送进程的detach之后:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23if (rank == src)
{
fprintf(stderr, "Before sending msg1 from proc %d, t = %f\n", rank, MPI_Wtime());
MPI_Bsend(msg1, MSG1LEN, MPI_CHAR, dest, 1, comm);
fprintf(stderr, "After sending msg1 from proc %d, t = %f\n", rank, MPI_Wtime());
...
MPI_Buffer_detach(&buf, &bufsize);
MPI_Barrier(comm);
}
else if (rank == dest)
{
MPI_Barrier(comm);
fprintf(stderr, "Before receiving msg1 on proc %d, t = %f\n", rank, MPI_Wtime());
MPI_Recv(rmsg1, MSG1LEN, MPI_CHAR, src, 1, comm, MPI_STATUS_IGNORE);
fprintf(stderr, "After receiving msg1 on proc %d, t = %f\n", rank, MPI_Wtime());
...
MPI_Buffer_detach(&buf, &bufsize);
}
执行结果遇上面相同,也就是说在释放发送端的缓冲区的时候消息一经发送完成,到了接收端的缓冲区中,因此这时候释放发送端缓冲区并不会有什么影响。
当然,如果在发送信息之前进行接受操作,而且在发送前设置阻塞函数,则就会发生死锁:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24if (rank == src)
{
MPI_Barrier(comm);
fprintf(stderr, "Before sending msg1 from proc %d, t = %f\n", rank, MPI_Wtime());
MPI_Bsend(msg1, MSG1LEN, MPI_CHAR, dest, 1, comm);
fprintf(stderr, "After sending msg1 from proc %d, t = %f\n", rank, MPI_Wtime());
...
MPI_Buffer_detach(&buf, &bufsize);
}
else if (rank == dest)
{
fprintf(stderr, "Before receiving msg1 on proc %d, t = %f\n", rank, MPI_Wtime());
MPI_Recv(rmsg1, MSG1LEN, MPI_CHAR, src, 1, comm, MPI_STATUS_IGNORE);
fprintf(stderr, "After receiving msg1 on proc %d, t = %f\n", rank, MPI_Wtime());
...
MPI_Barrier(comm);
MPI_Buffer_detach(&buf, &bufsize);
}
执行结果:1
2
3
4
5[zjshao@master ch02]$ mpicc bsendrecv.c -o bsendrecv.x
[zjshao@master ch02]$ mpiexec -host node01 -n 2 bsendrecv.x
Before receiving msg1 on proc 1, t = 1467965050.882681
[mpiexec@master.cluster] Sending Ctrl-C to processes as requested
[mpiexec@master.cluster] Press Ctrl-C again to force abort