机器学习算法实践-支持向量机(SVM)算法原理
前言
关于SVM的算法实践我打算分成多个部分进行总结。本文为第一部分主要介绍SVM的原理以及相关算法的简单推导,其中包括SVM原理,最初表达式,标准形式以及对偶形式(二次规划问题),形式变化过程中涉及到求解有约束优化问题的拉格朗日乘子法以及KKT条件等。
什么是支持向量机
对于线性可分两类数据,支持向量机就是条直线(对于高维数据点就是一个超平面), 两类数据点中的的分割线有无数条,SVM就是这无数条中最完美的一条,怎么样才算最完美呢?就是这条线距离两类数据点越远,则当有新的数据点的时候我们使用这条线将其分类的结果也就越可信。例如下图中的三条直线都可以将A中的数据分类,那条可以有最优的分类能力呢?
- 我们需要线找到数据点中距离分割超平面距离最近的点(找最小)
- 然后尽量使得距离超平面最近的点的距离的绝对值尽量的大(求最大)
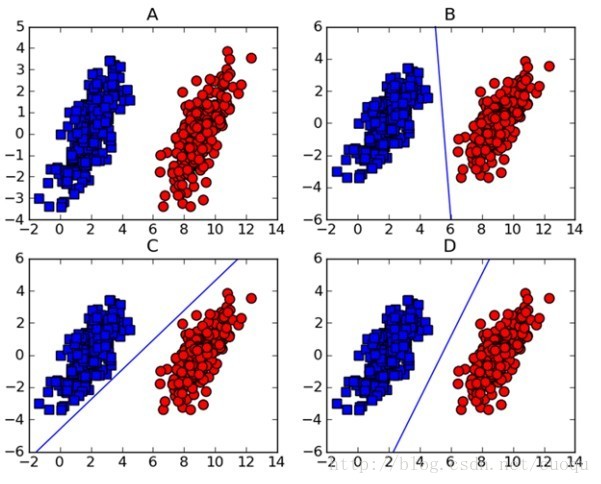
这里的数据点到超平面的距离就是间隔(margin), 当间隔越大,我们这条线(分类器)也就越健壮。
那些距离分割平面最近的点就是支持向量(Support Vectors).
求解支持向量机
本部分总结如何获取数据集的最优间隔分割平面(支持向量机)。
分割超平面
将一维直线和二维平面拓展到任意维, 分割超平面可以表示成:
$$
w^{T}x + b = 0
$$
其中$w$和$b$就是SVM的参数,不同的$w$和$b$确定不同的分割面.
这里我们可以回忆一下Logistic回归,在Logistic回归模型中,我们也同样将$z=w^{T}x$放入到sigmoid函数中来做极大似然估计获取最有的参数$w$,其中logistic模型中$w$中的$w_{0}$便对应着现在我们这里的截距$b$。
但是与Logistic回归中我们将$z=w^{T}x + b$代入到sigmoid函数中获取的值为1或者0也就是数据标签为0或1。而在SVM中我们对于二分类,不再使用0/1而是使用+1/-1作为数据类型标签。之所以使用+1/-1是为了能方便的使用间隔公式来表示数据点到分割面的间隔。
数据点与超平面的间隔
根据数据点到分割超平面的距离公式:
$$
d = \frac{1}{\lVert w \rVert} |w^{T}x + b|
$$
可见,在距离公式中有两个绝对值,其中分母上是常量,分子上则是与数据点相关的,如果数据点在分割平面上方,$w^{T}x + b > 0$; 数据点在分割平面下方,$w^{T}x + b < 0$。
这样我们在表示任意数据点到分割面的距离就会很麻烦,但是我们通过将数据标签设为+1/-1来讲距离统一用一个公式表示:
$$
d = y_{i} \cdot (w^{T}x + b) \cdot \frac{1}{\lVert w \rVert}
$$
这样,当数据点在分割面上方时,$y_{i} = 1$, $d > 0$且数据点距离分割面越远$d$越大;
当数据点在分割面下方时,$y_{i} = -1$, $d$扔大于$0$, 且数据点距离分割面越远$d$越大。
目标函数
我们现在已经有了间隔的公式,我们需要找到一组最好的$w$和$b$确定的分割超平面使得支持向量距离此平面的间隔最大。
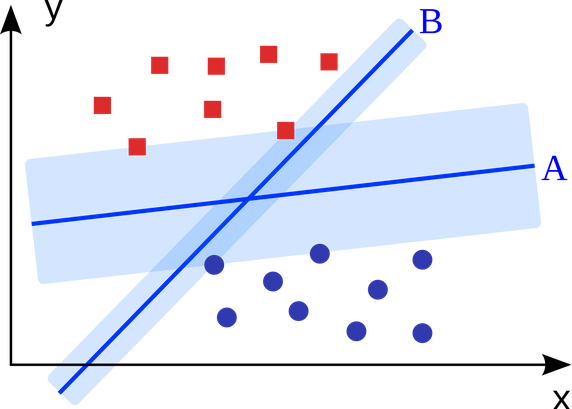
直接形式
直接使用公式表示:
$$
arg \max \limits_{w, b} \{ \min \limits_{n} (y_{i} \cdot (w^{T}x + b)) \cdot \frac{1}{\lVert w \rVert} \}
$$
通俗翻译下就是现在数据点中找到距离分割平面最近的点(支持向量),然后优化$w$和$b$来最大化支持向量到分割超平面的距离。
直接优化上面的式子很困难,我们需要做一些处理,使得同样的优化问题可以使我们用方便的优化算法来求解。
等比例改变参数$w$和$b$
首先看下分割超平面的一个性质。当我们等比例的扩大或缩小$w$和$b$并不会改变超平面的位置。例如对于位于三维空间中的二维平面$3x + 2y + z + 5 = 0$, $w=[3, 2, 1]^{T}$, $b = 5$,我们扩大或者缩小$w$和$b$并不会影响平面,即$\frac{3}{2} + y + \frac{1}{2}z = 0$与原始平面相同。
这样我们就可以任意等比例修改参数,来使我们优化的目标表达起来更加友好。
几何间隔和函数间隔
- 函数间隔(Functional Margin): $\hat{\gamma_{i}} = y_{i}(wx_{i}^{T} + b)$
- 几何间隔(Geometry Margin): $\gamma_{i} = y_{i}(\frac{wx_{i}^{T}}{\lVert w \rVert} + \frac{b}{\lVert w \rVert})$
可见由于我们可以等比例的改变参数,函数间隔相当于参数都乘上了$\lVert w \rVert$.
标准形式
我们的优化目标是最大化数据点到超平面的间隔,这里可以把最小化的部分(寻找支持向量)放到约束条件中, 有
$$
arg \max \limits_{w, b} \frac{\hat{\gamma}}{\lVert w \rVert}
$$
subject to
$$
y_{i} \cdot (wx_{i}^{T} + b) \ge \hat{\gamma}, i = 1,2,…,k
$$
其中$\hat{\gamma}$ 是支持向量到超平面的函数间隔。
我们将所有参数$w$和$b$除以$\hat{\gamma}$,便有$\hat{\gamma} = \min y_{i}(wx_{i}^{T} + b) = 1$, 于是有:
$$
arg \max \limits_{w, b} \frac{1}{\lVert w \rVert}
$$
subject to
$$
y_{i} \cdot (wx_{i}^{T} + b) \ge 1, i = 1,2,…,k
$$
将最大化问题转换为求最小值:
$$
arg \min \limits_{w, b} \frac{1}{2} \lVert w \rVert ^{2}
$$
subject to
$$
y_{i} \cdot (wx_{i}^{T} + b) \ge 1, i = 1,2,…,k
$$
这便是一个线性不等式约束下的二次优化问题, 下面我本就使用拉格朗日乘子法来获取我们优化目标的对偶形式。
通过拉格朗日乘子法和KKT条件将约束条件放入到目标函数中
拉格朗日乘数法是一种寻找多元函数在其变量受到一个或多个条件的约束时的极值的方法。这种方法可以将一个有n个变量与k个约束条件的最优化问题转换为一个解有n + k个变量的方程组的解的问题。这样我们可以将我们带约束的目标函数通过拉格朗日乘子法将约束放入到目标函数中方便优化。KKT条件是拉格朗日乘子法在约束条件为不等式的一种延伸。下面我就对拉格朗日乘子法和KKT条件进行下简单总结。
拉格朗日乘子法和KKT条件
我们从无约束优化到带有不等式约束条件逐渐介绍下几种不同类型的优化问题。
无约束优化问题
对于无约束优化问题
$$
\min \limits_{x} f(x)
$$
梯度$\nabla f(x) = 0$是局部最小点的必要条件,这样,优化问题的求解变成了对该必要条件解方程组。
带等式约束的优化问题
添加了等式限制条件,优化函数为: $\min \limits_{x} f(x)$, subject to $h(x) = 0$
拉格朗日乘子法就是通过引入新的位置变量(拉格朗日乘子)将上式的约束条件一起放到目标函数中:
$$
L(x, \lambda) = f(x) + \lambda h(x)
$$
subject to $h(x) = 0$
通过求解方程组: $\nabla L(x, \lambda) = 0; h(x) = 0$便可得到局部最小值的必要条件。
拉格朗日乘子法原理
我在这里稍微总结下Lagrange Multiplier的原理吧.
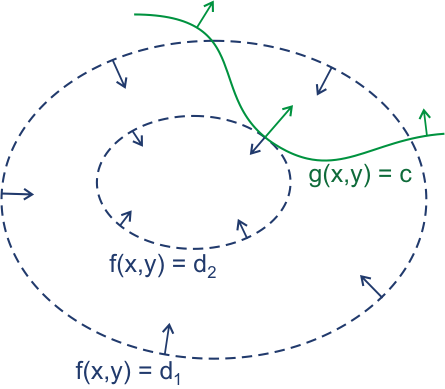
参考上图(忽略函数形式的差异),当约束条件$h(x) = 0$与$f(x)$的等高线相切的时候,切点具有局部最优值。此时$h(x^{*})$的梯度与$f(x^{*})$梯度同向,我们可以加入一个参数$\lambda$,得到他们之间的关系:
$$
\nabla f(x^{*}) + \lambda \nabla h(x^{*}) = 0
$$
上式便是对$L(x, \lambda) = f(x) + \lambda h(x)$ 求梯度等于0的结果, 这也就是拉格朗日函数了,其中那个关联梯度方向的$\lambda$就是拉格朗日乘子.
KKT条件
KKT条件是对于有不等式和等式约束的最优化问题具有局部最优解的必要条件。
因为是我们现在的SVM目标函数只有不等式约束没有等式约束,我们可以将优化问题写成:
$$
\min \limits_{x} f(x)
$$
subject to $g_{1}(x) \le 0, g_{2}(x) \le 0$ (这里我们列出两个约束条件)
对应的拉格朗日函数:
$$L(x, \mu_{1}, \mu_{2}) = f(x) + \mu_{1}g_{1}(x) + \mu_{2}g_{2}(x)$$
则KKT条件(具有局部最优点的必要条件)为:
- $\mu_{1} \ge 0, \mu_{2} \ge 0$
- $\nabla f(x) + \mu_{1} \nabla g_{1}(x) + \mu_{2} \nabla g_{2}(x) = 0$
- $\mu_{1}g(x) + \mu_{2}g(x) = 0$
不等式约束边界与目标函数的交接点不一定是切点了,如下图,如果两个不等式同时活跃(起作用),则约束条件与等高线相遇的点是在顶点上。
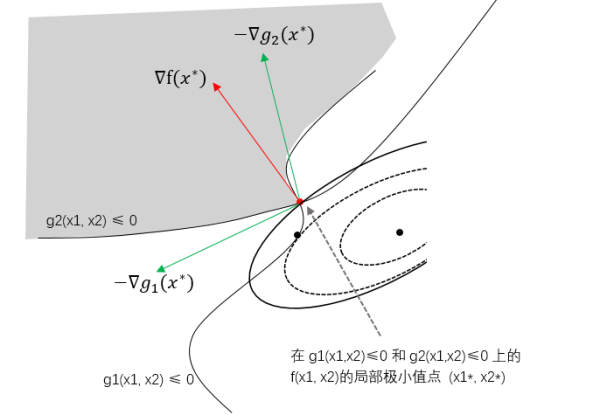
图片来源:https://www.zhihu.com/question/43830699/answer/129887370 ,侵删
等式约束函数和目标函数在切点的梯度方向同向,而不等式约束则有目标函数的梯度是约束函数在最优点的负梯度的线性组合(上图的红线和绿线), 于是我们便有约束和目标函数梯度的关系:
$$
\nabla f(x^{*}) = -\mu_{1} g_{1}(x^{*}) -\mu_{2} g_{2}(x^{*})
$$
其中$\mu_{1} \ge 0$, $\mu_{2} \ge 0$。
当然,最优点一定是在约束条件那条线上的,也就是满足
$$
g_{1}(x^{*}) = 0, g_{2}(x^{*}) = 0
$$
但是嘞,有的时候在最优点,不是所有的约束条件都起作用的。
对于有约束优化:
$$
\min \limits_{x} f(x)
$$
subject to $g_{1}(x) \le 0$, $g_{2}(x) \le 0$, $g_{3}(x) \le 0$
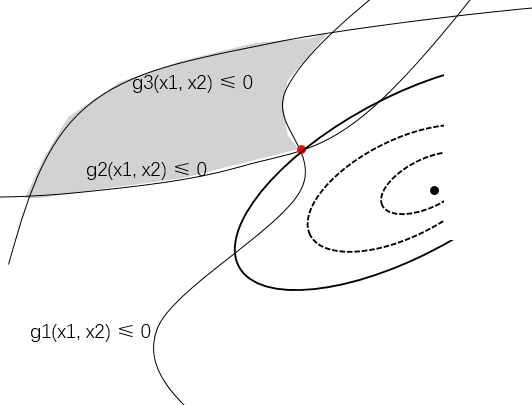
图片来源:https://www.zhihu.com/question/43830699/answer/129887370 ,侵删
如上图所示,$g_{3}(x) \le 0$约束条件并没有起作用,因此对于有三个约束条件的问题我们的另一个必要条件还可以写成:
$$
g_{1}(x^{*}) = 0, g_{2}(x^{*}) = 0
$$
为了统一表示,我们可以写成:
$$
\mu_{1}g_{1}(x^{*}) = 0; \mu_{2}g_{2}(x^{*}) = 0; \mu_{3}g_{3}(x^{*}) = 0
$$
由于$\mu_{i} \ge 0$,
- 当约束条件$g_{3}(x^{*})$不起作用时,$\mu_{3} = 0$,便得到了与$ g_{1}(x^{*}) = 0, g_{2}(x^{*}) = 0$相同的条件。
- 当约束条件起作用时,$\mu_{i} \gt 0$
继续SVM
SVM的拉格朗日函数
上面对拉格朗日乘子法和KKT条件进行了简单的总结,下面我们将其应用在SVM目标函数上。
我们现在求解SVM,是要进行带约束的优化问题:
$$
arg \min \limits_{w, b} \frac{1}{2} \lVert w \rVert ^{2}
$$
subject to
$$
1 - y_{i} \cdot (wx_{i}^{T} + b) \le 0, i = 1,2,…,k
$$
对应的拉格朗日函数:
$$
L(w, b, \alpha) = \frac{1}{2} \lVert w \rVert^{2} - \sum_{i=1}^{N} \alpha_{i}[y_{i}(w^{T}x_{i} + b) - 1]
$$
其中, $\alpha_{i} \ge 0$
令$g_{i}(w, b) = -y_{i}(w^{T}x_{i} + b) + 1$,则有$g_{i}(w, b) \le 0$.
- 如果$\alpha_{i} \gt 0$, 根据KKT条件$\alpha_{i}g_{i}(w, b) = 0$, 推出$g_{i}(w, b) = 0$, 则约束$g_{i} \le 0$ 是一个有效约束(active constraint), 对应的$x_{i}$为支持向量
- 如果$\alpha_{i} = 0$, 即$g_{i}(w, b) \lt 0$, $g_{i}(w, b) \le 0$ 为不起作用的约束,对应的$x_{i}$不是支持向量
可见,支持向量对应的约束为活动约束, 我们的目标函数是由支持向量决定的,毕竟我们就是支持向量机嘛.
对偶形式
接下来我们要获取目标函数的对偶问题,通过求解对偶问题的解来获取逼近SVM最优解的解。
$$
L(w, b, \alpha) = \frac{1}{2} \lVert w \rVert^{2} - \sum_{i=1}^{N} \alpha_{i}[y_{i}(w^{T}x_{i} + b) - 1]
$$
我们的目标是求$L(w, b, \alpha)$的最小值,因此我们先把$L$看成是$w, b$的函数,通过梯度为零获取获取极小值的必要条件:
$$
\theta_{D}(\alpha) = \min \limits_{w, b} L(w, b, \alpha)
$$
对于$w$: $\nabla _{w} L(w, b, \alpha) = w - \sum_{i=1}^{N} \alpha_{i} y_{i} x_{i} = 0$,得到$w = \sum_{i=1}^{N}\alpha_{i}y_{i}x_{i}$
我们可以看到,最终的参数$w$是输入向量的线性组合, $\alpha$就是其权重对于$b$: $\frac{\partial L}{\partial b} = -\sum_{i=1}^{N} \alpha_{i} y_{i} = 0$
将上面的到的式子回代,得到对偶形式:
$$w^{T}w = (\sum_{i=1}^{N}\alpha_{i}y_{i}x_{i})^{T}(\sum_{j=1}^{N}\alpha_{i} y_{i} x_{i}) = \sum_{i=1}^{N}\sum_{j=1}^{N}y_{i}y_{j}\alpha_{i}\alpha_{j} \langle x_{i}, x_{j} \rangle$$
$$W(\alpha) = \sum_{i=1}^{N}{\alpha_{i}} - \frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}y_{i}y_{j}\alpha_{i}\alpha_{j}\langle x_{i}, x_{j} \rangle$$
对偶问题:
$$
\max \limits_{\alpha} W(\alpha)
$$
subject to $\alpha_{i} \ge 0; \sum_{i=1}^{N}y_{i}\alpha_{i} = 0$
关于对偶问题,这里我也稍微做下简单的总结。
通过获取优化问题的对偶问题,我们可以通过优化对偶问题来逼近原问题的最优解。就好像我们上面的拉格朗日函数,我们先将函数看作$w, b$的函数,求最小值,然后再把函数看成拉格朗日乘子的函数,并求最大值逼近原始问题的最优解。
例如在SVM中的拉格朗日函数为:
$$
L(w, b, \alpha) = \frac{1}{2} \lVert w \rVert^{2} - \sum_{i=1}^{N} \alpha_{i}[y_{i}(w^{T}x_{i} + b) - 1]
$$
其中, $\sum_{i}^{N} \alpha_{i}[y_{i}(w^{T}x_{i} + b) - 1] \ge 0$ 可知,
$$\min L(w, b, \alpha) \le \min \frac{1}{2} \lVert w \rVert$$
因此我们需要求$\max \limits_{\alpha} W(\alpha)$来使得对偶问题的最大值接近原问题的最小值。
Ok. 最终我们的优化目标函数可以写成:
$$
arg \max \limits_{\alpha} [\sum_{i=1}^{N}{\alpha_{i}} - \frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}y_{i}y_{j}\alpha_{i}\alpha_{j}\langle x_{i}, x_{j} \rangle]
$$
约束条件: $\alpha_{i} \ge 0, \sum_{i=1}^{N}y_{i}\alpha_{i} = 0$
它是一个线性约束条件下多变量二次函数,一旦得到$\alpha$的解,便可以根据$\alpha$和$w$关系求出$w$,进而在得到$b$,于是我们就可以得到一个最优分割超平面。
总结
本文总结了SVM中的算法原理,其中包含了SVM中涉及到的拉格朗日乘子法和KKT条件的推导。并最终获取了目标函数的对偶形式,后面我将对对偶问题的求解算法进行总结。
参考
- 《Machine Learning in Action》
- https://en.wikipedia.org/wiki/Lagrange_multiplier
- 是否所有的优化问题都可以转化成对偶问题?
- 支持向量机(SVM)是什么意思?
- 如何通俗地讲解对偶问题?尤其是拉格朗日对偶lagrangian duality?