机器学习算法实践-SVM核函数和软间隔
前言
上文中简单总结了对于线性可分数据的SVM的算法原理,本文对于非线性可分以及有噪声存在的时候我们需要对基本SVM算法的改进进行下总结其中包括:
- 核函数在SVM算法中的使用
- 引入松弛变量和惩罚函数的软间隔分类器
SVM对偶问题
这里稍微回顾下SVM最终的对偶优化问题,因为后面的改进都是在对偶问题的形式上衍生的。
标准形式
$$\min \frac{1}{2} \lVert w \rVert ^{2}$$
subject to $y_{i}(w^{T}x_{i} + b) \ge 1$
对偶形式
$$arg \max \limits_{\alpha} \sum_{i=1}^{N} \alpha_{i} - \frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}y_{i}y_{j}\alpha_{i}\alpha_{j}\langle x_{i}, x_{j} \rangle$$
subject to $\alpha_{i} \ge 0$ ; $\sum_{i=1}^{N}\alpha_{i}y_{i}=0$
其中$w$和$\alpha$的关系:
$$w = \sum_{i=1}^{N}\alpha_{i}y_{i}x_{i}$$
SVM预测
SVM通过分割超平面$w^{T}x + b$来获取未知数据的类型,将上述$w$用$\alpha$替换得到
$$
h_{w, b}(x) = g(w^{T}x + b) = g(\sum_{i=1}^{N}\alpha_{i}y_{i} \langle x_{i}, x \rangle + b)
$$
通过$g(x)$输出+1或者-1来获取未知数据的类型预测.
核函数
对于分线性可分的数据我们通常需要将数据映射到高维空间中使得原本在低维空间线性不可分的数据在高维空间中线性可分。例如从一维映射到4维:
$$
x \xrightarrow{\phi(x)} \left[\begin{matrix}
x \\
x^{2} \\
x^{3} \\
x^{4} \\
\end{matrix} \right]
$$
然后对偶形式中也有数据向量的乘积,于是便可以进行替换:
$$
\langle x_{i}, x_{j} \rangle \rightarrow \langle \phi(x_{i}), \phi(x_{j}) \rangle
$$
但是呢,有时候$\phi(x)$会使得$x$维度太高,这样计算内积的复杂度很高,计算起来就会很困难,这个时候我们便需要核函数来拯救我们的计算复杂度。
我们需要使用一个函数来代替向量内积,但是这个核函数是可以表示成向量内积的形式的,只不过在计算结果的时候我们直接求函数值就好了,不需要做内积运算。这样复杂度会降低:
$$
K(x, z) = \langle \phi(x), \phi(z) \rangle
$$
核函数例子
这里总结下几个例子来对核函数的作用加深下理解.
对于$x, z \in \mathbb{R}^{n}$, 我们令核函数为:
$$K(x, z) = (x^{T}z)^{2} = (\sum_{i=1}^{N}x_{i}z_{i})^{2} = \sum_{i=1}^{N}\sum_{j=1}^{N} (x_{i}x_{j})(z_{i}z_{j}) = \langle \phi(x), \phi(z) \rangle$$
对于$x \in \mathbb{R}^{2}$, 这个时候$\phi(x)$的作用就相当于:
$$
\phi(x) = \left[ \begin{matrix}
x_{1}x_{1} \\
x_{1}x_{2} \\
x_{2}x_{1} \\
x_{2}x_{2} \\
\end{matrix} \right]
$$
那么我们可以分析下,如果没有引入核函数,我们需要计算维数为$n^{2}$的向量的内积,其运算时间复杂度为$O(n^{2})$。d但是通过核函数的引入我们不需要显式的计算向量内积了,而是直接计算核函数$(x^{T}z)^2$的值,计算核函数的值我们只需要计算一次维数为$n$的向量内积和一次平方运算,时间复杂度为$O(n)$。
可见,我们通过计算核函数,隐式的处理了一个维数很高的向量空间,降低了计算复杂度($O(n^{2} \rightarrow O(n)$)。
对于上面的核函数进行推广,我们可以有核函数:
$$
K(x, z) = (x^{T}z + C)^{2} = (x^{T}z)^{2} + 2C(x^{T}z) + c^{2}
$$
对于$x \in \mathbb{R}^{2}$, 这时$\phi(x)$相当于:
$$
\phi(x) = \left[ \begin{matrix}
x_{1}x_{1} \\
x_{1}x_{2} \\
x_{2}x_{1} \\
x_{2}x_{2} \\
\sqrt{2C}x_{1} \\
\sqrt{2C}x_{2} \\
C \\
\end{matrix} \right]
$$
这样我们将原本需要计算长度为$n^{2} + n + 1$的向量内积改成了直接计算两个长度为$n$的向量内积以及一个求和一次乘积运算。复杂度从$O(n^{2})$降到了$O(n)$
更通用的形式可以写成:
$$
K(x, z) = (x^{T}z + C)^{d}
$$
可见,在我们原始的SVM推导中,直接使用原始向量的内积便是这种形式的一种特殊形式,即$C = 0, d = 1$
另外,可以直观的看到,如果$\phi(x)$与$\phi(z)$的夹角比较小,则计算出来的$K(x, z)$就会比较大,相反如果$\phi(x)$与$\phi(z)$的夹角比较大,则核函数$K(x, z)$会比较小。所以核函数一定程度上是$\phi(x)$与$\phi(z)$相似度的度量。
高斯核函数(Gaussian kernel)
$$
K(x, z) = exp(-\frac{\lVert x - z \rVert^{2}}{2\sigma^{2}})
$$
通过高斯核函数的公式可以看出,如果$x$和$z$相差很小,则$K(x, z)$趋近于1, 相反如果相差很大则$K(x, z)$趋近于0。高斯核函数能够将数据映射到无限维空间,在无限维空间中,数据都是线性可分的。
核函数的合法性
判定核函数的合法性需要构造一个矩阵,即核函数矩阵$K$。
对于一个核函数$K(x, z)$以及$m$个训练数据$\left\{ x_{1}, x_{2}, …, x_{m} \right\}$, 核函数矩阵中的元素$K_{i,j}$定义如下:
$$K_{i, j} = K(x_{i}, x_{j})$$
现在在这里简单推导下核函数有效的必要条件:
若$K(x, z)$有效,则矩阵元素可写成(矩阵为对称矩阵)
$$
K_{i, j} = \phi(x_{i})^{T}\phi(x_{j}) = \phi(x_{j})^{T}\phi(x_{i}) = K_{i, j}
$$
对于向量$z$, 我们有:
$$
z^{T}Kz = \sum_{i} \sum_{j} z_{i}K_{i, j}z_{j} = \sum_{i} \sum_{j}z_{i}\phi(x_{i})^{T}\phi(x_{j})z_{j} = \sum_{i} \sum_{j} z_{i} (\sum_{k}\phi(x_{i})_{k} \phi(x_{j})_{k}) z_{j}
$$
$$
= \sum_{k} \sum_{i} \sum_{j} z_{i} \phi(x_{i})_{k} \phi(x_{j})_{k} z_{j} = \sum_{k}(\sum_{i} z_{i}\phi(x_{i})_{k})^{2} \ge 0
$$
此为矩阵$K$为半正定矩阵的必要条件。这就证明了,矩阵$K \ge 0$是对应核函数$K$有效的必要条件。当然他也是充分条件(参考Mercer’s theorem)
因此通过mercer定理我们可以不需要显式的去寻找核函数对应的$\phi(x)$而是构造核函数矩阵$K$,进而判断$K$是否半正定来判断核函数的有效性。
L1软间隔SVM(L1 soft margin SVM)
通过核函数将数据映射到高维空间能够增加数据线性可分的可能性,但是对于含有噪声的数据,优化出来的SVM可能不是我们最想要的,我们并不希望SVM会被噪声影响,因此我们可以通过引入松弛变量来使我们优化SVM时忽略掉噪声的影响,仅仅考虑那些真正有效的数据。
对于原始SVM标砖形式的约束条件:
$$
y_{i}(w^{T}x_{i} + b) \ge 1
$$
意味着所有数据点距离分割平面的距离都大于1.
但有的时候具有噪声,完全按照原始的约束条件,可能会是SVM发生较大的误差,如下图:
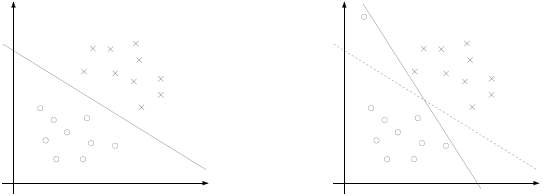
为了能让SVM忽略某些噪声,我们可以引入一个松弛变量$\xi_{i} \ge 0$来允许错误的分类发生,也就是允许有间隔小于1的数据点出现, 即:
$$
y_{i}(w^{T}x_{i} + b) \ge 1 - \xi_{i}
$$
但是只松弛约束条件可不行,我们同样要限制这种松弛,这时候我们需要在目标函数上加一个惩罚函数。
原始的目标函数为:
$$
arg \min \limits_{w, b} \frac{1}{2} \lVert w \rVert^{2}
$$
加入惩罚后:
$$
arg \min \limits_{w, b, \xi} \frac{1}{2} \lVert w \rVert^{2} + C\sum_{i=1}^{N}\xi_{i}
$$
其中$C$为惩罚因子来衡量惩罚的程度, C越大表明离群点越不被希望出现。
于是加上惩罚函数的SVM优化问题就变为:
$$
arg \min \limits_{w, b, \xi} \frac{1}{2} \lVert w \rVert^{2} + C\sum_{i=1}^{N}\xi_{i}
$$
subject to $y_{i}(w^{T} + b) \ge 1 - \xi_{i}$, $\xi_{i} \ge 0, i = 1, …, N$
然后我们求此问题的对偶问题,方法与原始SVM推导方法相同,使用拉格朗日乘子法,然后获取$w$的表达式,回代最后获得对偶形式:
$$
arg \max \limits_{\alpha} [\sum_{i=1}^{N}{\alpha_{i}} - \frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}y_{i}y_{j}\alpha_{i}\alpha_{j}\langle x_{i}, x_{j} \rangle]
$$
subject to $0 \le \alpha_{i} \le C$, $\sum_{i=1}^{m}\alpha_{i}y_{i} = 0$
可见,软间隔SVM的目标函数形式同硬间隔的形式相同,唯一不同的就在于$\alpha_{i}$的范围。
总结
本文对SVM中的核函数以及软间隔的原理进行了总结,对于非线性可分以及含有噪声的数据我们可以通过以上两种方法获得合适的分类器。后面将对目标函数的优化方法进行总结。