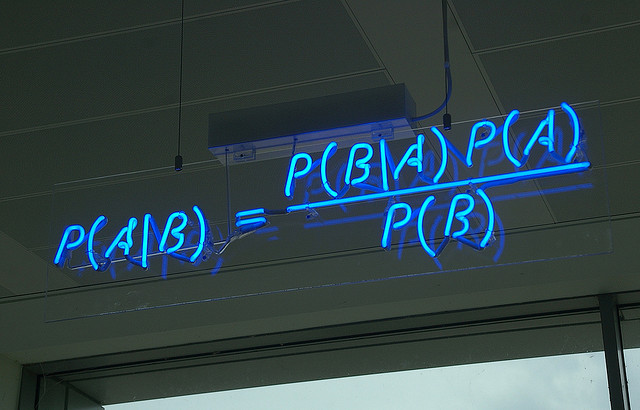
前言
上一篇总结了决策树的实现,本文中我将一步步实现一个朴素贝叶斯分类器,并采用SMS垃圾短信语料库中的数据进行模型训练,对垃圾短信进行过滤,在最后对分类的错误率进行了计算。
正文
与决策树分类和k近邻分类算法不同,贝叶斯分类主要借助概率论的知识来通过比较提供的数据属于每个类型的条件概率, 将他们分别计算出来然后预测具有最大条件概率的那个类别是最后的类别。当然样本越多我们统计的不同类型的特征值分布就越准确,使用此分布进行预测则会更加准确。
上一篇总结了决策树的实现,本文中我将一步步实现一个朴素贝叶斯分类器,并采用SMS垃圾短信语料库中的数据进行模型训练,对垃圾短信进行过滤,在最后对分类的错误率进行了计算。
与决策树分类和k近邻分类算法不同,贝叶斯分类主要借助概率论的知识来通过比较提供的数据属于每个类型的条件概率, 将他们分别计算出来然后预测具有最大条件概率的那个类别是最后的类别。当然样本越多我们统计的不同类型的特征值分布就越准确,使用此分布进行预测则会更加准确。
最近打算系统学习下机器学习的基础算法,避免眼高手低,决定把常用的机器学习基础算法都实现一遍以便加深印象。本文为这系列博客的第一篇,关于决策树(Decision Tree)的算法实现,文中我将对决策树种涉及到的算法进行总结并附上自己相关的实现代码。所有算法代码以及用于相应模型的训练的数据都会放到GitHub上(https://github.com/PytLab/MLBox).
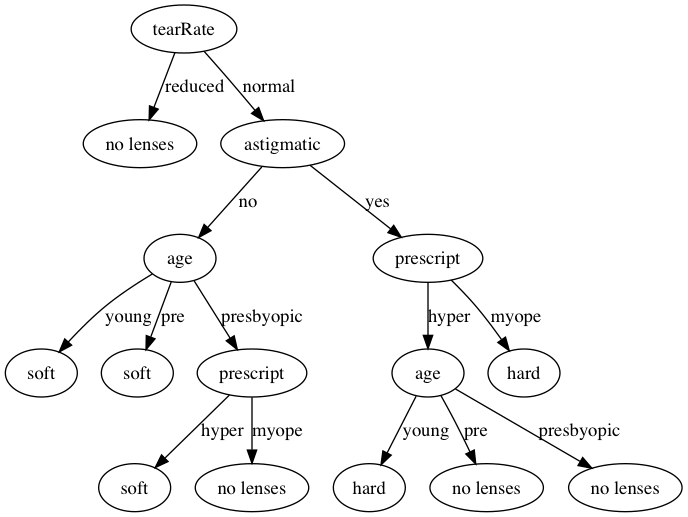
本文中我将一步步通过MLiA的隐形眼镜处方数集构建决策树并使用Graphviz将决策树可视化。
前两周花了些时间给自己的动力学程序Kynetix和KMCLibX写了个web界面方便别人使用,目前程序完成了计算微观动力学的部分,并部署在了腾讯云上http://123.206.225.154:5000/, 程序命名为KinLab (https://github.com/PytLab/kynetix-webapp).
目前KinLab主要包含四个部分:
文件系统这里我模仿jupyternotebook写的,因为着急实现主要的计算过程,这里一些常用的文件操作还没实现(后续有时间会加上),正常可以在任何路径下创建或者打开一个作业设置界面。
最近在给自己的动力学模拟程序写个web界面,目前采用了bootstrap + flask的组合, 看了下bootstrap的一些组件样式和内置的插件的使用,在实现自己的网站的时候肯定会有自己的需求,于是需要开发或者扩展Bootstrap插件,这里就总结下开发Bootstrap插件的步骤。
Bootstrap插件本质上就是一个jQuery插件,除了将插件函数绑定到jQuery的原型对象上以外,Bootstrap还需要遵守一些其他的额外的步骤方便维护和学习等。

最近在看算导决定抽空把算法基础在夯实一遍, 算法相关的实现代码时不时会丢到GitHub上,主要以C++实现,也会有相应的Python和Javascript的实现。
在这里,作为算法的渐近分析的标准方法之一,对几种渐近记号进行下总结.
所有的渐近记号都表示一个函数的集合.
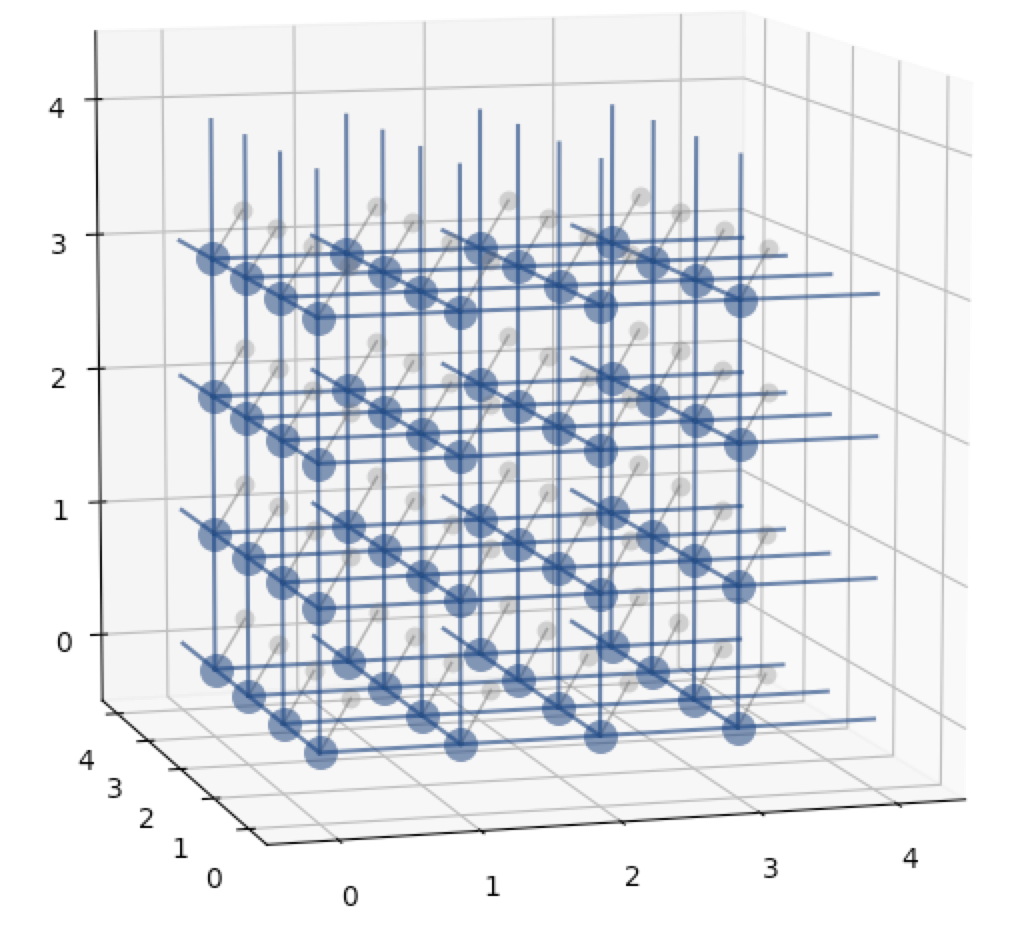
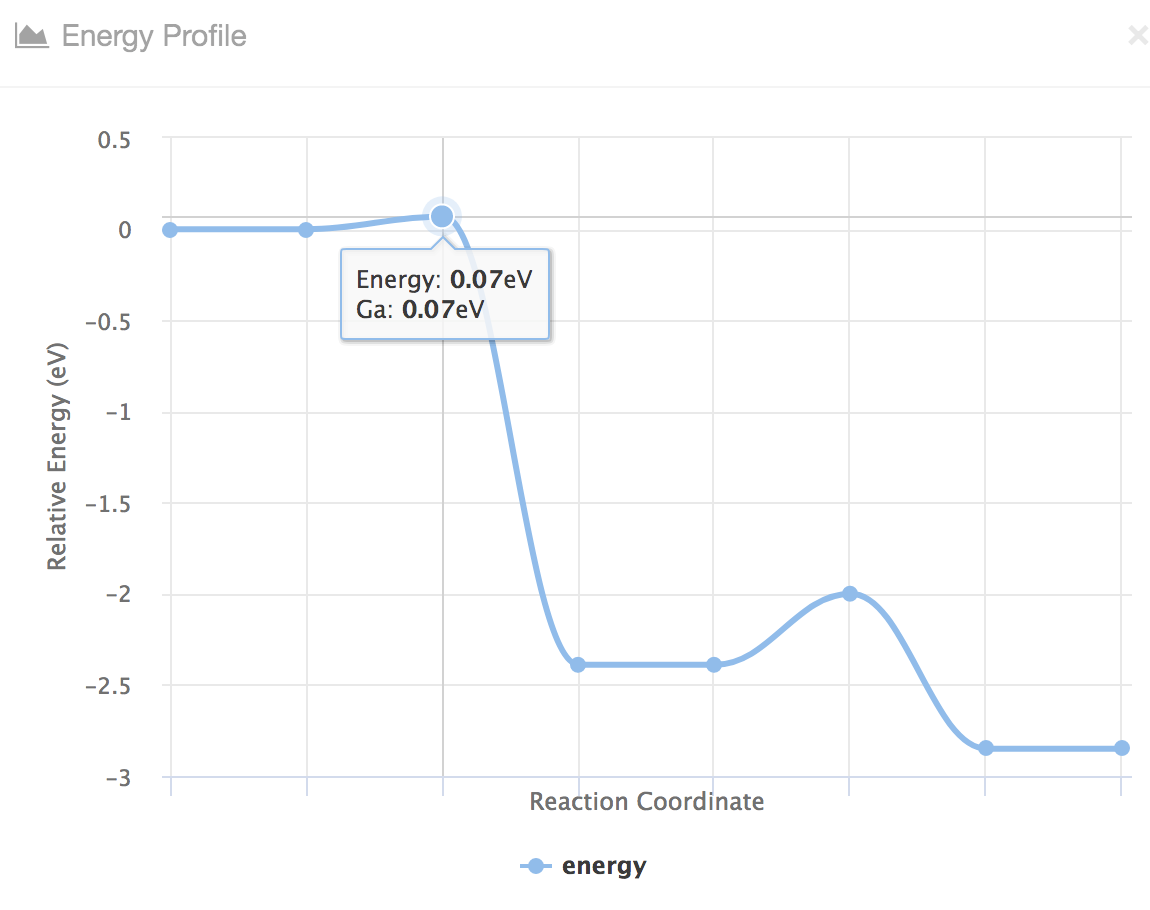
最近在写文章需要绘制一些一维的能量曲线(energy profile)和抽象的二维和三维的网格来表示晶体用来描述自己的算法,于是自己在之前的脚本的基础上进行了整改写成了只提供接口的Python库,基本思想就是封装了matplotlib中相关接口,方便快速搭建和定制自己的能量曲线和网格结构, 代码托管在GitHub上并上传至PyPI。对于研究晶体材料的同学如果想通过python来绘制简单的晶格图像可以参考一下。